NVIDIA stated it has achieved a document massive language mannequin (LLM) inference velocity, asserting that an NVIDIA DGX B200 node with eight NVIDIA Blackwell GPUs achieved greater than 1,000 tokens per second (TPS) per consumer on the 400-billion-parameter Llama 4 Maverick mannequin.
NVIDIA stated the mannequin is the most important and strongest within the Llama 4 assortment and that the velocity was independently measured by the AI benchmarking service Synthetic Evaluation.
NVIDIA added that Blackwell reaches 72,000 TPS/server at their highest throughput configuration.
The corporate stated it made software program optimizations utilizing TensorRT-LLM and educated a speculative decoding draft mannequin utilizing EAGLE-3 strategies. Combining these approaches, NVIDIA has achieved a 4x speed-up relative to the very best prior Blackwell baseline, NVIDIA stated.
“The optimizations described under considerably improve efficiency whereas preserving response accuracy,” NVIDIA stated in a weblog posted yesterday. “We leveraged FP8 information varieties for GEMMs, Combination of Consultants (MoE), and Consideration operations to scale back the mannequin dimension and make use of the excessive FP8 throughput attainable with Blackwell Tensor Core expertise. Accuracy when utilizing the FP8 information format matches that of Synthetic Evaluation BF16 throughout many metrics….”Most generative AI utility contexts require a stability of throughput and latency, making certain that many purchasers can concurrently get pleasure from a “ok” expertise. Nevertheless, for crucial functions that should make necessary choices at velocity, minimizing latency for a single shopper turns into paramount. Because the TPS/consumer document reveals, Blackwell {hardware} is your best option for any activity—whether or not you should maximize throughput, stability throughput and latency, or reduce latency for a single consumer (the main target of this put up).
Under is an outline of the kernel optimizations and fusions (denoted in red-dashed squares) NVIDIA utilized throughout the inference. NVIDIA applied a number of low-latency GEMM kernels, and utilized varied kernel fusions (like FC13 + SwiGLU, FC_QKV + attn_scaling and AllReduce + RMSnorm) to ensure Blackwell excels on the minimal latency state of affairs.
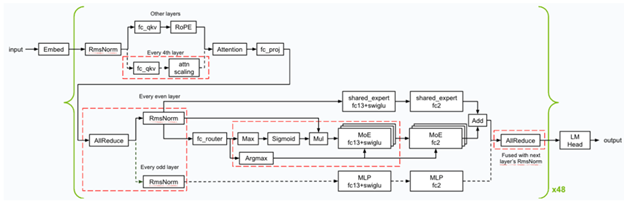
Overview of the kernel optimizations & fusions used for Llama 4 Maverick
NVIDIA optimized the CUDA kernels for GEMMs, MoE, and Consideration operations to attain the very best efficiency on the Blackwell GPUs.


- Utilized spatial partitioning (also referred to as warp specialization) and designed the GEMM kernels to load information from reminiscence in an environment friendly method to maximise utilization of the big reminiscence bandwidth that the NVIDIA DGX system gives—64TB/s HBM3e bandwidth in complete.
- Shuffled the GEMM weight in a swizzled format to permit higher format when loading the computation end result from Tensor Reminiscence after the matrix multiplication computations utilizing Blackwell’s fifth-generation Tensor Cores.
- Optimized the efficiency of the eye kernels by dividing the computations alongside the sequence size dimension of the Okay and V tensors, permitting computations to run in parallel throughout a number of CUDA thread blocks. As well as, NVIDIA utilized distributed shared reminiscence to effectively cut back outcomes throughout the thread blocks in the identical thread block cluster with out the necessity to entry the worldwide reminiscence.
The rest of the weblog might be discovered right here.











{kind=link}