On this tutorial, we exhibit learn how to construct a strong and clever question-answering system by combining the strengths of Tavily Search API, Chroma, Google Gemini LLMs, and the LangChain framework. The pipeline leverages real-time internet search utilizing Tavily, semantic doc caching with Chroma vector retailer, and contextual response technology by means of the Gemini mannequin. These instruments are built-in by means of LangChain’s modular elements, comparable to RunnableLambda, ChatPromptTemplate, ConversationBufferMemory, and GoogleGenerativeAIEmbeddings. It goes past easy Q&A by introducing a hybrid retrieval mechanism that checks for cached embeddings earlier than invoking contemporary internet searches. The retrieved paperwork are intelligently formatted, summarized, and handed by means of a structured LLM immediate, with consideration to supply attribution, consumer historical past, and confidence scoring. Key features comparable to superior immediate engineering, sentiment and entity evaluation, and dynamic vector retailer updates make this pipeline appropriate for superior use instances like analysis help, domain-specific summarization, and clever brokers.
!pip set up -qU langchain-community tavily-python langchain-google-genai streamlit matplotlib pandas tiktoken chromadb langchain_core pydantic langchainWe set up and improve a complete set of libraries required to construct a sophisticated AI search assistant. It consists of instruments for retrieval (tavily-python, chromadb), LLM integration (langchain-google-genai, langchain), knowledge dealing with (pandas, pydantic), visualization (matplotlib, streamlit), and tokenization (tiktoken). These elements kind the core basis for establishing a real-time, context-aware QA system.
import os
import getpass
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import json
import time
from typing import Listing, Dict, Any, Optionally available
from datetime import datetimeWe import important Python libraries used all through the pocket book. It consists of commonplace libraries for atmosphere variables, safe enter, time monitoring, and knowledge varieties (os, getpass, time, typing, datetime). Moreover, it brings in core knowledge science instruments like pandas, matplotlib, and numpy for knowledge dealing with, visualization, and numerical computations, in addition to json for parsing structured knowledge.
if "TAVILY_API_KEY" not in os.environ:
os.environ["TAVILY_API_KEY"] = getpass.getpass("Enter Tavily API key: ")
if "GOOGLE_API_KEY" not in os.environ:
os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter Google API key: ")
import logging
logging.basicConfig(degree=logging.INFO, format="%(asctime)s - %(title)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)We securely initialize API keys for Tavily and Google Gemini by prompting customers provided that they’re not already set within the atmosphere, making certain protected and repeatable entry to exterior providers. It additionally configures a standardized logging setup utilizing Python’s logging module, which helps monitor execution circulation and seize debug or error messages all through the pocket book.
from langchain_community.retrievers import TavilySearchAPIRetriever
from langchain_community.vectorstores import Chroma
from langchain_core.paperwork import Doc
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
from langchain.reminiscence import ConversationBufferMemoryWe import key elements from the LangChain ecosystem and its integrations. It brings within the TavilySearchAPIRetriever for real-time internet search, Chroma for vector storage, and GoogleGenerativeAI modules for chat and embedding fashions. Core LangChain modules like ChatPromptTemplate, RunnableLambda, ConversationBufferMemory, and output parsers allow versatile immediate development, reminiscence dealing with, and pipeline execution.
class SearchQueryError(Exception):
"""Exception raised for errors within the search question."""
cross
def format_docs(docs):
formatted_content = []
for i, doc in enumerate(docs):
metadata = doc.metadata
supply = metadata.get('supply', 'Unknown supply')
title = metadata.get('title', 'Untitled')
rating = metadata.get('rating', 0)
formatted_content.append(
f"Doc {i+1} [Score: {score:.2f}]:n"
f"Title: {title}n"
f"Supply: {supply}n"
f"Content material: {doc.page_content}n"
)
return "nn".be part of(formatted_content)We outline two important elements for search and doc dealing with. The SearchQueryError class creates a customized exception to handle invalid or failed search queries gracefully. The format_docs operate processes a listing of retrieved paperwork by extracting metadata comparable to title, supply, and relevance rating and formatting them right into a clear, readable string.
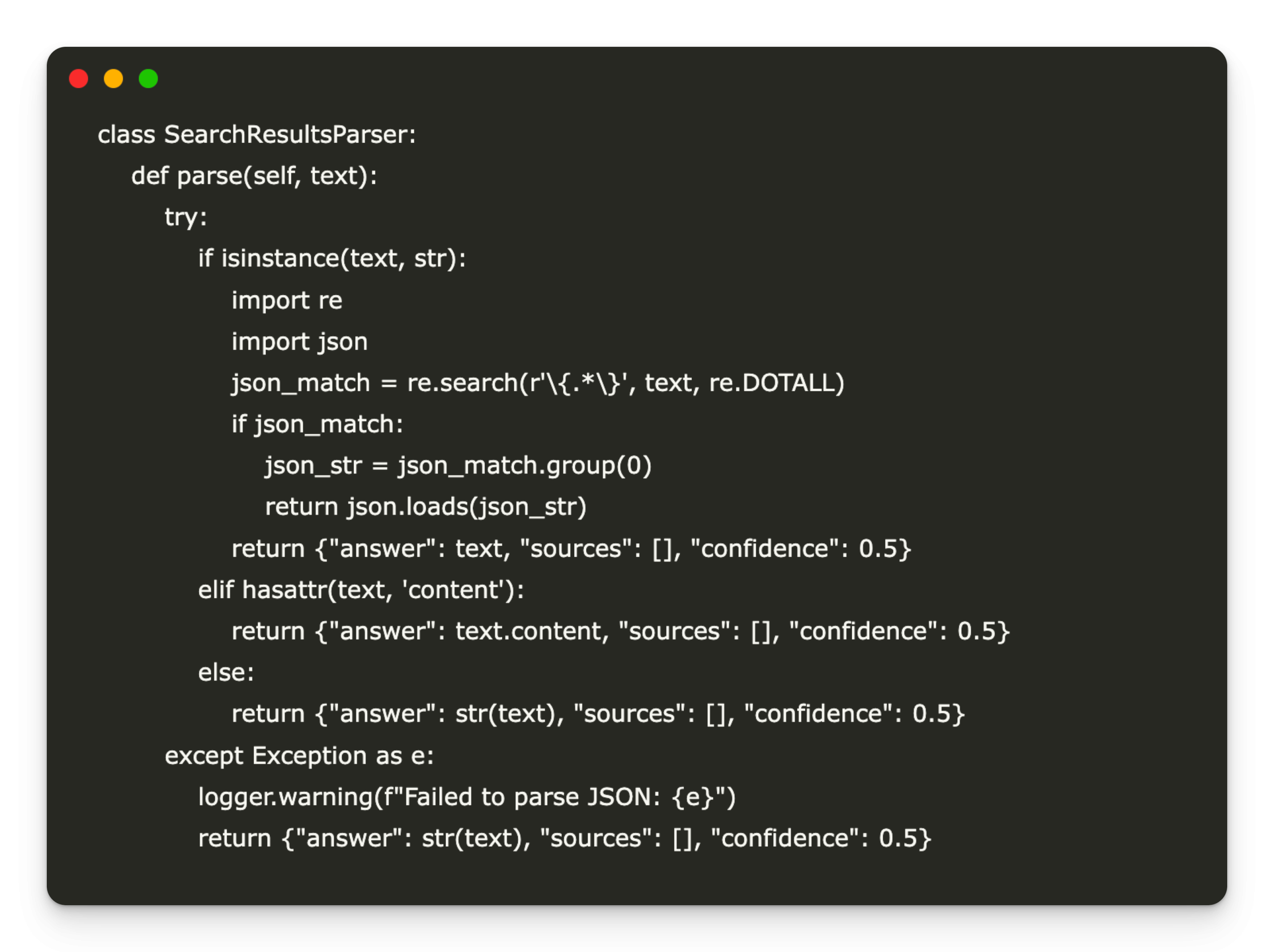
class SearchResultsParser:
def parse(self, textual content):
attempt:
if isinstance(textual content, str):
import re
import json
json_match = re.search(r'{.*}', textual content, re.DOTALL)
if json_match:
json_str = json_match.group(0)
return json.masses(json_str)
return {"reply": textual content, "sources": [], "confidence": 0.5}
elif hasattr(textual content, 'content material'):
return {"reply": textual content.content material, "sources": [], "confidence": 0.5}
else:
return {"reply": str(textual content), "sources": [], "confidence": 0.5}
besides Exception as e:
logger.warning(f"Did not parse JSON: {e}")
return {"reply": str(textual content), "sources": [], "confidence": 0.5}The SearchResultsParser class supplies a sturdy methodology for extracting structured info from LLM responses. It makes an attempt to parse a JSON-like string from the mannequin output, returning to a plain textual content response format if parsing fails. It gracefully handles string outputs and message objects, making certain constant downstream processing. In case of errors, it logs a warning and returns a fallback response containing the uncooked reply, empty sources, and a default confidence rating, enhancing the system’s fault tolerance.
class EnhancedTavilyRetriever:
def __init__(self, api_key=None, max_results=5, search_depth="superior", include_domains=None, exclude_domains=None):
self.api_key = api_key
self.max_results = max_results
self.search_depth = search_depth
self.include_domains = include_domains or []
self.exclude_domains = exclude_domains or []
self.retriever = self._create_retriever()
self.previous_searches = []
def _create_retriever(self):
attempt:
return TavilySearchAPIRetriever(
api_key=self.api_key,
ok=self.max_results,
search_depth=self.search_depth,
include_domains=self.include_domains,
exclude_domains=self.exclude_domains
)
besides Exception as e:
logger.error(f"Did not create Tavily retriever: {e}")
increase
def invoke(self, question, **kwargs):
if not question or not question.strip():
increase SearchQueryError("Empty search question")
attempt:
start_time = time.time()
outcomes = self.retriever.invoke(question, **kwargs)
end_time = time.time()
search_record = {
"timestamp": datetime.now().isoformat(),
"question": question,
"num_results": len(outcomes),
"response_time": end_time - start_time
}
self.previous_searches.append(search_record)
return outcomes
besides Exception as e:
logger.error(f"Search failed: {e}")
increase SearchQueryError(f"Did not carry out search: {str(e)}")
def get_search_history(self):
return self.previous_searchesThe EnhancedTavilyRetriever class is a customized wrapper across the TavilySearchAPIRetriever, including higher flexibility, management, and traceability to go looking operations. It helps superior options like limiting search depth, area inclusion/exclusion filters, and configurable outcome counts. The invoke methodology performs internet searches and tracks every question’s metadata (timestamp, response time, and outcome depend), storing it for later evaluation.
class SearchCache:
def __init__(self):
self.embedding_function = GoogleGenerativeAIEmbeddings(mannequin="fashions/embedding-001")
self.vector_store = None
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
def add_documents(self, paperwork):
if not paperwork:
return
attempt:
if self.vector_store is None:
self.vector_store = Chroma.from_documents(
paperwork=paperwork,
embedding=self.embedding_function
)
else:
self.vector_store.add_documents(paperwork)
besides Exception as e:
logger.error(f"Failed so as to add paperwork to cache: {e}")
def search(self, question, ok=3):
if self.vector_store is None:
return []
attempt:
return self.vector_store.similarity_search(question, ok=ok)
besides Exception as e:
logger.error(f"Vector search failed: {e}")
return []The SearchCache class implements a semantic caching layer that shops and retrieves paperwork utilizing vector embeddings for environment friendly similarity search. It makes use of GoogleGenerativeAIEmbeddings to transform paperwork into dense vectors and shops them in a Chroma vector database. The add_documents methodology initializes or updates the vector retailer, whereas the search methodology allows quick retrieval of probably the most related cached paperwork based mostly on semantic similarity. This reduces redundant API calls and improves response occasions for repeated or associated queries, serving as a light-weight hybrid reminiscence layer within the AI assistant pipeline.
search_cache = SearchCache()
enhanced_retriever = EnhancedTavilyRetriever(max_results=5)
reminiscence = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
system_template = """You're a analysis assistant that gives correct solutions based mostly on the search outcomes supplied.
Observe these tips:
1. Solely use the context supplied to reply the query
2. If the context would not comprise the reply, say "I haven't got enough info to reply this query."
3. Cite your sources by referencing the doc numbers
4. Do not make up info
5. Hold the reply concise however full
Context: {context}
Chat Historical past: {chat_history}
"""
system_message = SystemMessagePromptTemplate.from_template(system_template)
human_template = "Query: {query}"
human_message = HumanMessagePromptTemplate.from_template(human_template)
immediate = ChatPromptTemplate.from_messages([system_message, human_message])
We initialize the core elements of the AI assistant: a semantic SearchCache, the EnhancedTavilyRetriever for web-based querying, and a ConversationBufferMemory to retain chat historical past throughout turns. It additionally defines a structured immediate utilizing ChatPromptTemplate, guiding the LLM to behave as a analysis assistant. The immediate enforces strict guidelines for factual accuracy, context utilization, supply quotation, and concise answering, making certain dependable and grounded responses.
def get_llm(model_name="gemini-2.0-flash-lite", temperature=0.2, response_mode="json"):
attempt:
return ChatGoogleGenerativeAI(
mannequin=model_name,
temperature=temperature,
convert_system_message_to_human=True,
top_p=0.95,
top_k=40,
max_output_tokens=2048
)
besides Exception as e:
logger.error(f"Did not initialize LLM: {e}")
increase
output_parser = SearchResultsParser()
We outline the get_llm operate, which initializes a Google Gemini language mannequin with configurable parameters comparable to mannequin title, temperature, and decoding settings (e.g., top_p, top_k, and max tokens). It ensures robustness with error dealing with for failed mannequin initialization. An occasion of SearchResultsParser can also be created to standardize and construction the LLM’s uncooked responses, enabling constant downstream processing of solutions and metadata.
def plot_search_metrics(search_history):
if not search_history:
print("No search historical past obtainable")
return
df = pd.DataFrame(search_history)
plt.determine(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(vary(len(df)), df['response_time'], marker="o")
plt.title('Search Response Occasions')
plt.xlabel('Search Index')
plt.ylabel('Time (seconds)')
plt.grid(True)
plt.subplot(1, 2, 2)
plt.bar(vary(len(df)), df['num_results'])
plt.title('Variety of Outcomes per Search')
plt.xlabel('Search Index')
plt.ylabel('Variety of Outcomes')
plt.grid(True)
plt.tight_layout()
plt.present()
The plot_search_metrics operate visualizes efficiency traits from previous queries utilizing Matplotlib. It converts the search historical past right into a DataFrame and plots two subgraphs: one displaying response time per search and the opposite displaying the variety of outcomes returned. This aids in analyzing the system’s effectivity and search high quality over time, serving to builders fine-tune the retriever or determine bottlenecks in real-world utilization.
def retrieve_with_fallback(question):
cached_results = search_cache.search(question)
if cached_results:
logger.information(f"Retrieved {len(cached_results)} paperwork from cache")
return cached_results
logger.information("No cache hit, performing internet search")
search_results = enhanced_retriever.invoke(question)
search_cache.add_documents(search_results)
return search_results
def summarize_documents(paperwork, question):
llm = get_llm(temperature=0)
summarize_prompt = ChatPromptTemplate.from_template(
"""Create a concise abstract of the next paperwork associated to this question: {question}
{paperwork}
Present a complete abstract that addresses the important thing factors related to the question.
"""
)
chain = (
{"paperwork": lambda docs: format_docs(docs), "question": lambda _: question}
| summarize_prompt
| llm
| StrOutputParser()
)
return chain.invoke(paperwork)These two features improve the assistant’s intelligence and effectivity. The retrieve_with_fallback operate implements a hybrid retrieval mechanism: it first makes an attempt to fetch semantically related paperwork from the native Chroma cache and, if unsuccessful, falls again to a real-time Tavily internet search, caching the brand new outcomes for future use. In the meantime, summarize_documents leverages a Gemini LLM to generate concise summaries from retrieved paperwork, guided by a structured immediate that ensures relevance to the question. Collectively, they permit low-latency, informative, and context-aware responses.
def advanced_chain(query_engine="enhanced", mannequin="gemini-1.5-pro", include_history=True):
llm = get_llm(model_name=mannequin)
if query_engine == "enhanced":
retriever = lambda question: retrieve_with_fallback(question)
else:
retriever = enhanced_retriever.invoke
def chain_with_history(input_dict):
question = input_dict["question"]
chat_history = reminiscence.load_memory_variables({})["chat_history"] if include_history else []
docs = retriever(question)
context = format_docs(docs)
outcome = immediate.invoke({
"context": context,
"query": question,
"chat_history": chat_history
})
reminiscence.save_context({"enter": question}, {"output": outcome.content material})
return llm.invoke(outcome)
return RunnableLambda(chain_with_history) | StrOutputParser()The advanced_chain operate defines a modular, end-to-end reasoning workflow for answering consumer queries utilizing cached or real-time search. It initializes the required Gemini mannequin, selects the retrieval technique (cached fallback or direct search), constructs a response pipeline incorporating chat historical past (if enabled), codecs paperwork into context, and prompts the LLM utilizing a system-guided template. The chain additionally logs the interplay in reminiscence and returns the ultimate reply, parsed into clear textual content. This design allows versatile experimentation with fashions and retrieval methods whereas sustaining dialog coherence.
qa_chain = advanced_chain()
def analyze_query(question):
llm = get_llm(temperature=0)
analysis_prompt = ChatPromptTemplate.from_template(
"""Analyze the next question and supply:
1. Essential matter
2. Sentiment (constructive, damaging, impartial)
3. Key entities talked about
4. Question kind (factual, opinion, how-to, and many others.)
Question: {question}
Return the evaluation in JSON format with the next construction:
{{
"matter": "primary matter",
"sentiment": "sentiment",
"entities": ["entity1", "entity2"],
"kind": "question kind"
}}
"""
)
chain = analysis_prompt | llm | output_parser
return chain.invoke({"question": question})
print("Superior Tavily-Gemini Implementation")
print("="*50)
question = "what 12 months was breath of the wild launched and what was its reception?"
print(f"Question: {question}")We initialize the ultimate elements of the clever assistant. qa_chain is the assembled reasoning pipeline able to course of consumer queries utilizing retrieval, reminiscence, and Gemini-based response technology. The analyze_query operate performs a light-weight semantic evaluation on a question, extracting the primary matter, sentiment, entities, and question kind utilizing the Gemini mannequin and a structured JSON immediate. The instance question, about Breath of the Wild’s launch and reception, showcases how the assistant is triggered and ready for full-stack inference and semantic interpretation. The printed heading marks the beginning of interactive execution.
attempt:
print("nSearching for reply...")
reply = qa_chain.invoke({"query": question})
print("nAnswer:")
print(reply)
print("nAnalyzing question...")
attempt:
query_analysis = analyze_query(question)
print("nQuery Evaluation:")
print(json.dumps(query_analysis, indent=2))
besides Exception as e:
print(f"Question evaluation error (non-critical): {e}")
besides Exception as e:
print(f"Error in search: {e}")
historical past = enhanced_retriever.get_search_history()
print("nSearch Historical past:")
for i, h in enumerate(historical past):
print(f"{i+1}. Question: {h['query']} - Outcomes: {h['num_results']} - Time: {h['response_time']:.2f}s")
print("nAdvanced search with area filtering:")
specialized_retriever = EnhancedTavilyRetriever(
max_results=3,
search_depth="superior",
include_domains=["nintendo.com", "zelda.com"],
exclude_domains=["reddit.com", "twitter.com"]
)
attempt:
specialized_results = specialized_retriever.invoke("breath of the wild gross sales")
print(f"Discovered {len(specialized_results)} specialised outcomes")
abstract = summarize_documents(specialized_results, "breath of the wild gross sales")
print("nSummary of specialised outcomes:")
print(abstract)
besides Exception as e:
print(f"Error in specialised search: {e}")
print("nSearch Metrics:")
plot_search_metrics(historical past)
We exhibit the whole pipeline in motion. It performs a search utilizing the qa_chain, shows the generated reply, after which analyzes the question for sentiment, matter, entities, and sort. It additionally retrieves and prints every question’s search historical past, response time, and outcome depend. Additionally, it runs a domain-filtered search targeted on Nintendo-related websites, summarizes the outcomes, and visualizes search efficiency utilizing plot_search_metrics, providing a complete view of the assistant’s capabilities in real-time use.
In conclusion, following this tutorial offers customers a complete blueprint for making a extremely succesful, context-aware, and scalable RAG system that bridges real-time internet intelligence with conversational AI. The Tavily Search API lets customers straight pull contemporary and related content material from the online. The Gemini LLM provides strong reasoning and summarization capabilities, whereas LangChain’s abstraction layer permits seamless orchestration between reminiscence, embeddings, and mannequin outputs. The implementation consists of superior options comparable to domain-specific filtering, question evaluation (sentiment, matter, and entity extraction), and fallback methods utilizing a semantic vector cache constructed with Chroma and GoogleGenerativeAIEmbeddings. Additionally, structured logging, error dealing with, and analytics dashboards present transparency and diagnostics for real-world deployment.
Try the Colab Pocket book. All credit score for this analysis goes to the researchers of this mission. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 90k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.













{kind=link}