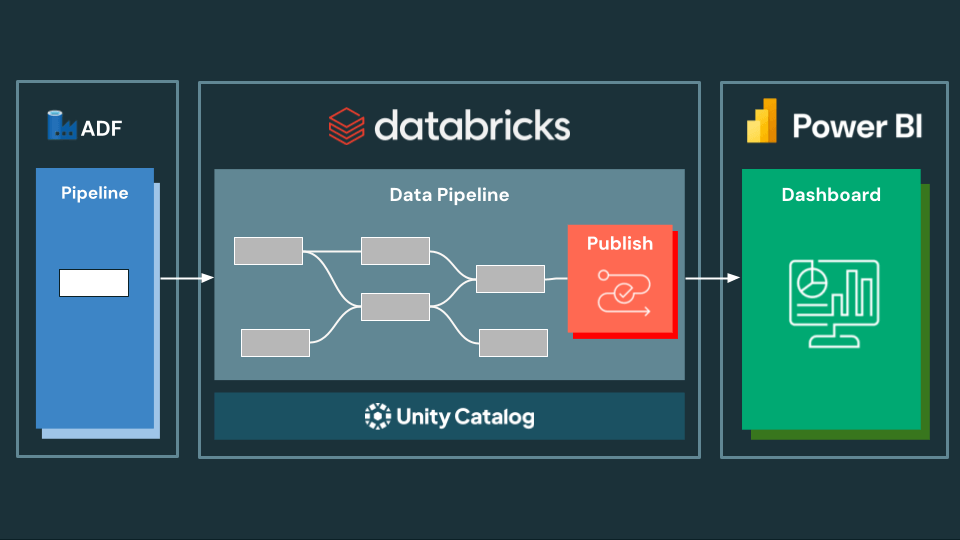


Azure Databricks is a first-party Microsoft service, natively built-in with the Azure ecosystem to unify knowledge and AI with high-performance analytics and deep tooling help. This tight integration now features a native Databricks Job exercise in Azure Knowledge Manufacturing facility (ADF), making it simpler than ever to set off Databricks Workflows immediately inside ADF.
This new exercise in ADF is a right away finest observe, and all ADF and Azure Databricks customers ought to take into account transferring to this sample.
The brand new Databricks Job exercise could be very easy to make use of:
- In your ADF pipeline, drag the Databricks Job exercise onto the display
- On the Azure Databricks tab, choose a Databricks linked service for authentication to the Azure Databricks workspace
- You possibly can authenticate utilizing one among these choices:
- a PAT token
- the ADF system assigned managed identification, or
- a person assigned managed identification
- Though the linked service requires you to configure a cluster, this cluster is neither created nor used when executing this exercise. It’s retained for compatibility with different exercise sorts
- You possibly can authenticate utilizing one among these choices:

3. On the settings tab, choose a Databricks Workflow to execute within the Job drop down checklist (you’ll solely see the Jobs your authenticated principal has entry to). Within the Job Parameters part beneath, configure Job Parameters (if any) to ship to the Databricks Workflow. To know extra about Databricks Job Parameters, please verify the docs.
- Be aware that the Job and Job Parameters may be configured with dynamic content material

That’s all there’s to it. ADF will kick off your Databricks Workflow and provides again the Job Run ID and URL. ADF will then ballot for the Job Run to finish. Learn extra beneath to study why this new sample is an prompt basic.

Kicking off Databricks Workflows from ADF allows you to get extra horsepower out of your Azure Databricks funding
Utilizing Azure Knowledge Manufacturing facility and Azure Databricks collectively has been a GA sample since 2018 when it was launched with this weblog submit. Since then, the mixing has been a staple for Azure prospects who’ve primarily been following this easy sample:
- Use ADF to land knowledge into Azure storage through its 100+ connectors utilizing a self-hosted integration runtime for personal or on-premise connections
- Orchestrate Databricks Notebooks through the native Databricks Pocket book exercise to implement scalable knowledge transformation in Databricks utilizing Delta Lake tables in ADLS
Whereas this sample has been extraordinarily beneficial over time, it has constrained prospects into the next modes of operation, which rob them of the total worth of Databricks:
- Utilizing All Goal compute to run Jobs to stop cluster launch instances -> run into noisy neighbor issues and paying for All function compute for automated jobs
- Ready for cluster launches per Pocket book execution when utilizing Jobs compute -> basic clusters are spun up per pocket book execution, incurring cluster launch time for every, even for a DAG of notebooks
- Managing Swimming pools to scale back Job cluster launch instances -> swimming pools may be exhausting to handle and might usually result in paying for VMs that aren’t being utilized
- Utilizing a very permissive permissions sample for integration between ADF and Azure Databricks -> the mixing requires workspace admin OR the create cluster entitlement
- No capability to make use of new options in Databricks like Databricks SQL, DLT, or Serverless
Whereas this sample is scalable and native to Azure Knowledge Manufacturing facility and Azure Databricks, the tooling and capabilities it provides have remained the identical since its launch in 2018, regardless that Databricks has grown leaps and bounds into the market-leading Knowledge Intelligence Platform throughout all clouds.
Azure Databricks goes past conventional analytics to ship a unified Knowledge Intelligence Platform on Azure. It combines industry-leading Lakehouse structure with built-in AI and superior governance to assist prospects unlock insights sooner, at decrease price, and with enterprise-grade safety. Key capabilities embrace:
- OSS and Open requirements
- An {industry} main Lakehouse Catalog by means of Unity Catalog for securing knowledge and AI throughout code, languages, and compute inside and out of doors of Azure Databricks
- Greatest-in-class efficiency and value efficiency for ETL
- Constructed-in capabilities for conventional ML and GenAI, together with fine-tuning LLMs, utilizing foundational fashions (together with Claude Sonnet), constructing Agent purposes, and serving fashions
- Greatest-in-class DW on the lakehouse with Databricks SQL
- Automated publishing and integration with Energy BI by means of the Publish to Energy BI performance present in Unity Catalog and Workflows
With the discharge of the native Databricks Job exercise in Azure Knowledge Manufacturing facility, prospects can now execute Databricks Workflows and move parameters to the Jobs Runs. This new sample not solely solves for the constraints highlighted above, nevertheless it additionally permits for the utilization of the next options in Databricks that had been not beforehand out there in ADF like:
- Programming a DAG of Duties inside Databricks
- Utilizing Databricks SQL integrations
- Executing DLT pipelines
- Utilizing dbt integration with a SQL Warehouse
- Utilizing Traditional Job Cluster reuse to scale back cluster launch instances
- Utilizing Serverless Jobs compute
- Normal Databricks Workflow performance like Run As, Activity Values, Conditional Executions like If/Else and For Every, AI/BI Activity, Restore Runs, Notifications/Alerts, Git integration, DABs help, built-in lineage, queuing and concurrent runs, and way more…
Most significantly, prospects can now use the ADF Databricks Job exercise to leverage the Publish to Energy BI Duties in Databricks Workflows, which is able to robotically publish Semantic Fashions to the Energy BI Service from schemas in Unity Catalog and set off an Import if there are tables with storage modes utilizing Import or Twin (arrange directions documentation). A demo on Energy BI Duties in Databricks Workflows may be discovered right here. To enhance this, take a look at the Energy BI on Databricks Greatest Practices Cheat Sheet – a concise, actionable information that helps groups configure and optimize their experiences for efficiency, price, and person expertise from the beginning.


The Databricks Job exercise in ADF is the New Greatest Observe
Utilizing the Databricks Job exercise in Azure Knowledge Manufacturing facility to kick off Databricks Workflows is the brand new finest observe integration when utilizing the 2 instruments. Prospects can instantly begin utilizing this sample to make the most of the entire capabilities within the Databricks Knowledge Intelligence Platform. For patrons utilizing ADF, utilizing the ADF Databricks Job exercise will lead to fast enterprise worth and price financial savings. Prospects with ETL frameworks which can be utilizing Pocket book actions ought to migrate their frameworks to make use of Databricks Workflows and the brand new ADF Databricks Job exercise and prioritize this initiative of their roadmap.
Get Began with a Free 14-day Trial of Azure Databricks.











{kind=link}