
Glue-execution-role, within the client account, with the next insurance policies:
- AWS managed insurance policies
AWSGlueServiceRoleandAmazonRedshiftDataFullAccess. - Create a brand new in-line coverage with the next permissions and fix it:
- Add the next belief coverage to
Glue-execution-role, permitting AWS Glue to imagine this function:
Steps for producer account setup
For the producer account setup, you’ll be able to both use your IAM administrator function added as Lake Formation administrator or use a Lake Formation administrator function with permissions added as mentioned within the conditions. For illustration functions, we use the IAM admin function Admin added as Lake Formation administrator.

Configure your catalog
Full the next steps to arrange your catalog:
- Log in to AWS Administration Console as
Admin. - On the Amazon Redshift console, observe the directions in Registering Amazon Redshift clusters and namespaces to the AWS Glue Knowledge Catalog.
- After the registration is initiated, you will notice the invite from Amazon Redshift on the Lake Formation console.
- Choose the pending catalog invitation and select Approve and create catalog.

- On the Set catalog particulars web page, configure your catalog:
- For Identify, enter a reputation (for this submit,
redshiftserverless1-uswest2). - Choose Entry this catalog from Apache Iceberg suitable engines.
- Select the IAM function you created for the information switch.
- Select Subsequent.

- For Identify, enter a reputation (for this submit,
- On the Grant permissions – non-obligatory web page, select Add permissions.
- Grant the
Adminconsumer Tremendous consumer permissions for Catalog permissions and Grantable permissions. - Select Add.

- Grant the
- Confirm the granted permission on the subsequent web page and select Subsequent.

- Assessment the small print on the Assessment and create web page and select Create catalog.

Wait a couple of seconds for the catalog to indicate up.
- Select Catalogs within the navigation pane and confirm that the
redshiftserverless1-uswest2catalog is created.
- Discover the catalog element web page to confirm the
ordersdb.publicdatabase.
- On the database View dropdown menu, view the desk and confirm that the
orderstbldesk reveals up.
Because the Admin function, you can even question the orderstbl in Amazon Athena and make sure the information is obtainable.

Grant permissions on the tables from the producer account to the buyer account
On this step, we share the Amazon Redshift federated catalog database redshiftserverless1-uswest2:ordersdb.public and desk orderstbl in addition to the Amazon S3 based mostly Iceberg desk returnstbl_iceberg and its database customerdb from the default catalog to the buyer account. We are able to’t share your entire catalog to exterior accounts as a catalog-level permission; we simply share the database and desk.
- On the Lake Formation console, select Knowledge permissions within the navigation pane.
- Select Grant.

- Beneath Principals, choose Exterior accounts.
- Present the buyer account ID.
- Beneath LF-Tags or catalog sources, choose Named Knowledge Catalog sources.
- For Catalogs, select the account ID that represents the default catalog.
- For Databases, select
customerdb.
- Beneath Database permissions, choose Describe beneath Database permissions and Grantable permissions.
- Select Grant.

- Repeat these steps and grant table-level Choose and Describe permissions on
returnstbl_iceberg. - Repeat these steps once more to grant database- and table-level permissions for the
ordertbldesk of the federated catalog databaseredshiftserverless1-uswest2/ordersdb.
The next screenshots present the configuration for database-level permissions.


The next screenshots present the configuration for table-level permissions.


- Select Knowledge permissions within the navigation pane and confirm that the buyer account has been granted database- and table-level permissions for each
orderstblfrom the federated catalog andreturnstbl_icebergfrom the default catalog.
Register the Amazon S3 location of the returnstbl_iceberg with Lake Formation.
On this step, we register the Amazon S3 based mostly Iceberg desk returnstbl_iceberg information location with Lake Formation to be managed by Lake Formation permissions. Full the next steps:
- On the Lake Formation console, select Knowledge lake places within the navigation pane.
- Select Register location.

- For Amazon S3 path, enter the trail in your S3 bucket that you just supplied whereas creating the Iceberg desk
returnstbl_iceberg. - For IAM function, present the user-defined function
LakeFormationS3Registration_customthat you just created as a prerequisite. - For Permission mode, choose Lake Formation.
- Select Register location.

- Select Knowledge lake places within the navigation pane to confirm the Amazon S3 registration.

With this step, the producer account setup is full.
Steps for client account setup
For the buyer account setup, we use the IAM admin function Admin, added as a Lake Formation administrator.
The steps within the client account are fairly concerned. Within the client account, a Lake Formation administrator will settle for the AWS Useful resource Entry Supervisor (AWS RAM) shares and create the required useful resource hyperlinks that time to the shared catalog, database, and tables. The Lake Formation admin verifies that the shared sources are accessible by working check queries in Athena. The admin additional grants permissions to the function Glue-execution-role on the useful resource hyperlinks, database, and tables. The admin then runs a be part of question in AWS Glue 5.0 Spark utilizing Glue-execution-role.
Settle for and confirm the shared sources
Lake Formation makes use of AWS RAM shares to allow cross-account sharing with Knowledge Catalog useful resource insurance policies within the AWS RAM insurance policies. To view and confirm the shared sources from producer account, full the next steps:
- Log in to the buyer AWS console and set the AWS Area to match the producer’s shared useful resource Area. For this submit, we use
us-west-2. - Open the Lake Formation console. You will notice a message indicating there’s a pending invite and asking you settle for it on the AWS RAM console.

- Observe the directions in Accepting a useful resource share invitation from AWS RAM to evaluate and settle for the pending invitations.
- When the invite standing adjustments to Accepted, select Shared sources beneath Shared with me within the navigation pane.
- Confirm that the Redshift Serverless federated catalog
redshiftserverless1-uswest2, the default catalog databasecustomerdb, the deskreturnstbl_iceberg, and the producer account ID beneath Proprietor ID column show appropriately.
- On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Databases.
- Search by the producer account ID.
You need to see thecustomerdbandpublicdatabases. You possibly can additional choose every database and select View tables on the Actions dropdown menu and confirm the desk names

You’ll not see an AWS RAM share invite for the catalog stage on the Lake Formation console, as a result of catalog-level sharing isn’t attainable. You possibly can evaluate the shared federated catalog and Amazon Redshift managed catalog names on the AWS RAM console, or utilizing the AWS Command Line Interface (AWS CLI) or SDK.
Create a catalog hyperlink container and useful resource hyperlinks
A catalog hyperlink container is a Knowledge Catalog object that references an area or cross-account federated database-level catalog from different AWS accounts. For extra particulars, seek advice from Accessing a shared federated catalog. Catalog hyperlink containers are primarily Lake Formation useful resource hyperlinks on the catalog stage that reference or level to a Redshift cluster federated catalog or Amazon Redshift managed catalog object from different accounts.
Within the following steps, we create a catalog hyperlink container that factors to the producer shared federated catalog redshiftserverless1-uswest2. Contained in the catalog hyperlink container, we create a database. Contained in the database, we create a useful resource hyperlink for the desk that factors to the shared federated catalog desk >:redshiftserverless1-uswest2/ordersdb.public.orderstbl.
- On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Catalogs.
- Select Create catalog.

- Present the next particulars for the catalog:
- For Identify, enter a reputation for the catalog (for this submit,
rl_link_container_ordersdb). - For Sort, select Catalog Hyperlink container.
- For Supply, select Redshift.
- For Goal Redshift Catalog, enter the Amazon Useful resource Identify (ARN) of the producer federated catalog (
arn:aws:glue:us-west-2:>:catalog/redshiftserverless1-uswest2/ordersdb). - Beneath Entry from engines, choose Entry this catalog from Apache Iceberg suitable engines.
- For IAM function, present the Redshift-S3 information switch function that you just had created within the conditions.
- Select Subsequent.
- For Identify, enter a reputation for the catalog (for this submit,

- On the Grant permissions – non-obligatory web page, select Add permissions.
- Grant the
Adminconsumer Tremendous consumer permissions for Catalog permissions and Grantable permissions. - Select Add after which select Subsequent.
- Grant the

- Assessment the small print on the Assessment and create web page and select Create catalog.
Wait a couple of seconds for the catalog to indicate up.

- Within the navigation pane, select Catalogs.
- Confirm that
rl_link_container_ordersdbis created.

Create a database beneath rl_link_container_ordersdb
Full the next steps:
- On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Databases.
- On the Select catalog dropdown menu, select
rl_link_container_ordersdb. - Select Create database.
Alternatively, you’ll be able to select the Create dropdown menu after which select Database.
- Present particulars for the database:
- For Identify, enter a reputation (for this submit,
public_db). - For Catalog, select
rl_link_container_ordersdb. - Go away Location – non-obligatory as clean.
- Beneath Default permissions for newly created tables, deselect Use solely IAM entry management for brand spanking new tables on this database.
- Select Create database.
- For Identify, enter a reputation (for this submit,

- Select Catalogs within the navigation pane to confirm that
public_dbis created beneathrl_link_container_ordersdb.

Create a desk useful resource hyperlink for the shared federated catalog desk
A useful resource hyperlink to a shared federated catalog desk can reside solely contained in the database of a catalog hyperlink container. A useful resource hyperlink for such tables won’t work if created contained in the default catalog. For extra particulars on useful resource hyperlinks, seek advice from Making a useful resource hyperlink to a shared Knowledge Catalog desk.
Full the next steps to create a desk useful resource hyperlink:
- On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Tables.
- On the Create dropdown menu, select Useful resource hyperlink.

- Present particulars for the desk useful resource hyperlink:
- For Useful resource hyperlink identify, enter a reputation (for this submit,
rl_orderstbl). - For Vacation spot catalog, select
rl_link_container_ordersdb. - For Database, select
public_db. - For Shared desk’s area, select US West (Oregon).
- For Shared desk, select
orderstbl. - After the Shared desk is chosen, Shared desk’s database and Shared desk’s catalog ID ought to get routinely populated.
- Select Create.
- For Useful resource hyperlink identify, enter a reputation (for this submit,

- Within the navigation pane, select Databases to confirm that
rl_orderstblis created beneathpublic_db, insiderl_link_container_ordersdb.


Create a database useful resource hyperlink for the shared default catalog database.
Now we create a database useful resource hyperlink within the default catalog to question the Amazon S3 based mostly Iceberg desk shared from the producer. For particulars on database useful resource hyperlinks, refer Making a useful resource hyperlink to a shared Knowledge Catalog database.
Although we’re in a position to see the shared database within the default catalog of the buyer, a useful resource hyperlink is required to question from analytics engines, akin to Athena, Amazon EMR, and AWS Glue. When utilizing AWS Glue with Lake Formation tables, the useful resource hyperlink must be named identically to the supply account’s useful resource. For extra particulars on utilizing AWS Glue with Lake Formation, seek advice from Issues and limitations.
Full the next steps to create a database useful resource hyperlink:
- On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Databases.
- On the Select catalog dropdown menu, select the account ID to decide on the default catalog.
- Seek for
customerdb.
You need to see the shared database identify customerdb with the Proprietor account ID as that of your producer account ID.
- Choose
customerdb, and on the Create dropdown menu, select Useful resource hyperlink. - Present particulars for the useful resource hyperlink:
- For Useful resource hyperlink identify, enter a reputation (for this submit,
customerdb). - The remainder of the fields must be already populated.
- Select Create.
- For Useful resource hyperlink identify, enter a reputation (for this submit,
- Within the navigation pane, select Databases and confirm that
customerdbis created beneath the default catalog. Useful resource hyperlink names will present in italicized font.

Confirm entry as Admin utilizing Athena
Now you’ll be able to confirm your entry utilizing Athena. Full the next steps:
- Open the Athena console.
- Ensure that an S3 bucket is supplied to retailer the Athena question outcomes. For particulars, seek advice from Specify a question end result location utilizing the Athena console.
- Within the navigation pane, confirm each the default catalog and federated catalog tables by previewing them.
- You too can run a be part of question as follows. Take note of the three-point notation for referring to the tables from two totally different catalogs:

This verifies the brand new functionality of SageMaker Lakehouse, which permits accessing Redshift cluster tables and Amazon S3 based mostly Iceberg tables in the identical question, throughout AWS accounts, by way of the Knowledge Catalog, utilizing Lake Formation permissions.
Grant permissions to Glue-execution-role
Now we are going to share the sources from the producer account with further IAM principals within the client account. Normally, the information lake admin grants permissions to information analysts, information scientists, and information engineers within the client account to do their job capabilities, akin to processing and analyzing the information.
We arrange Lake Formation permissions on the catalog hyperlink container, databases, tables, and useful resource hyperlinks to the AWS Glue job execution function Glue-execution-role that we created within the conditions.
Useful resource hyperlinks enable solely Describe and Drop permissions. It’s essential to use the Grant heading in the right direction configuration to supply database Describe and desk Choose permissions.
Full the next steps:
- On the Lake Formation console, select Knowledge permissions within the navigation pane.
- Select Grant.
- Beneath Principals, choose IAM customers and roles.
- For IAM customers and roles, enter
Glue-execution-role. - Beneath LF-Tags or catalog sources, choose Named Knowledge Catalog sources.
- For Catalogs, select
rl_link_container_ordersdband the buyer account ID, which signifies the default catalog. - Beneath Catalog permissions, choose Describe for Catalog permissions.
- Select Grant.


- Repeat these steps for the catalog
rl_link_container_ordersdb:- On the Databases dropdown menu, select
public_db. - Beneath Database permissions, choose Describe.
- Select Grant.
- On the Databases dropdown menu, select
- Repeat these steps once more, however after selecting
rl_link_container_ordersdbandpublic_db, on the Tables dropdown menu, selectrl_orderstbl.- Beneath Useful resource hyperlink permissions, choose Describe.
- Select Grant.
- Repeat these steps to grant further permissions to
Glue-execution-role.- For this iteration, grant Describe permissions on the default catalog databases
publicandcustomerdb. - Grant Describe permission on the useful resource hyperlink
customerdb. - Grant Choose permission on the tables
returnstbl_icebergandorderstbl.
- For this iteration, grant Describe permissions on the default catalog databases
The next screenshots present the configuration for database public and customerdb permissions.


The next screenshots present the configuration for useful resource hyperlink customerdb permissions.


The next screenshots present the configuration for desk returnstbl_iceberg permissions.


The next screenshots present the configuration for desk orderstbl permissions.


- Within the navigation pane, select Knowledge permissions and confirm permissions on
Glue-execution-role.

Run a PySpark job in AWS Glue 5.0
Obtain the PySpark script LakeHouseGlueSparkJob.py. This AWS Glue PySpark script runs Spark SQL by becoming a member of the producer shared federated orderstbl desk and Amazon S3 based mostly returns desk within the client account to research the information and establish the entire orders positioned per market.
Exchange > within the script together with your client account ID. Full the next steps to create and run an AWS Glue job:
- On the AWS Glue console, within the navigation pane, select ETL jobs.
- Select Create job, then select Script editor.

- For Engine, select Spark.
- For Choices, select Begin contemporary.
- Select Add script.
- Browse to the situation the place you downloaded and edited the script, choose the script, and select Open.
- On the Job particulars tab, present the next data:
- For Identify, enter a reputation (for this submit,
LakeHouseGlueSparkJob). - Beneath Fundamental properties, for IAM function, select
Glue-execution-role. - For Glue model, choose Glue 5.0.
- Beneath Superior properties, for Job parameters, select Add new parameter.
- Add the parameters
--datalake-formats = icebergand--enable-lakeformation-fine-grained-access = true.
- For Identify, enter a reputation (for this submit,
- Save the job.
- Select Run to execute the AWS Glue job, and await the job to finish.
- Assessment the job run particulars from the Output logs


Clear up
To keep away from incurring prices in your AWS accounts, clear up the sources you created:
- Delete the Lake Formation permissions, catalog hyperlink container, database, and tables within the client account.
- Delete the AWS Glue job within the client account.
- Delete the federated catalog, database, and desk sources within the producer account.
- Delete the Redshift Serverless namespace within the producer account.
- Delete the S3 buckets you created as a part of information switch in each accounts and the Athena question outcomes bucket within the client account.
- Clear up the IAM roles you created for the SageMaker Lakehouse setup as a part of the conditions.
Conclusion
On this submit, we illustrated methods to convey your present Redshift tables to SageMaker Lakehouse and share them securely with exterior AWS accounts. We additionally confirmed methods to question the shared information warehouse and information lakehouse tables in the identical Spark session, from a recipient account, utilizing Spark in AWS Glue 5.0.
We hope you discover this convenient to combine your Redshift tables with an present information mesh and entry the tables utilizing AWS Glue Spark. Take a look at this resolution in your accounts and share suggestions within the feedback part. Keep tuned for extra updates and be happy to discover the options of SageMaker Lakehouse and AWS Glue variations.
Appendix: Desk creation
Full the next steps to create a returns desk within the Amazon S3 based mostly default catalog and an orders desk in Amazon Redshift:
- Obtain the CSV format datasets orders and returns.
- Add them to your S3 bucket beneath the corresponding desk prefix path.
- Use the next SQL statements in Athena. First-time customers of Athena ought to seek advice from Specify a question end result location.

- Create an Iceberg format desk within the default catalog and insert information from the CSV format desk:

- To create the orders desk within the Redshift Serverless namespace, open the Question Editor v2 on the Amazon Redshift console.
- Hook up with the default namespace utilizing your database admin consumer credentials.
- Run the next instructions within the SQL editor to create the database
ordersdband desk orderstbl in it. Copy the information out of your S3 location of the orders information to theorderstbl:
Concerning the Authors
 Aarthi Srinivasan is a Senior Huge Knowledge Architect with Amazon SageMaker Lakehouse. She collaborates with the service crew to reinforce product options, works with AWS prospects and companions to architect lakehouse options, and establishes finest practices for information governance.
Aarthi Srinivasan is a Senior Huge Knowledge Architect with Amazon SageMaker Lakehouse. She collaborates with the service crew to reinforce product options, works with AWS prospects and companions to architect lakehouse options, and establishes finest practices for information governance.
 Subhasis Sarkar is a Senior Knowledge Engineer with Amazon. Subhasis thrives on fixing advanced technological challenges with modern options. He focuses on AWS information architectures, notably information mesh implementations utilizing AWS CDK elements.
Subhasis Sarkar is a Senior Knowledge Engineer with Amazon. Subhasis thrives on fixing advanced technological challenges with modern options. He focuses on AWS information architectures, notably information mesh implementations utilizing AWS CDK elements.
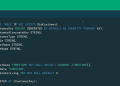
Glue-execution-role, within the client account, with the next insurance policies:
- AWS managed insurance policies
AWSGlueServiceRoleandAmazonRedshiftDataFullAccess. - Create a brand new in-line coverage with the next permissions and fix it:
- Add the next belief coverage to
Glue-execution-role, permitting AWS Glue to imagine this function:
Steps for producer account setup
For the producer account setup, you’ll be able to both use your IAM administrator function added as Lake Formation administrator or use a Lake Formation administrator function with permissions added as mentioned within the conditions. For illustration functions, we use the IAM admin function Admin added as Lake Formation administrator.
Configure your catalog
Full the next steps to arrange your catalog:
- Log in to AWS Administration Console as
Admin. - On the Amazon Redshift console, observe the directions in Registering Amazon Redshift clusters and namespaces to the AWS Glue Knowledge Catalog.
- After the registration is initiated, you will notice the invite from Amazon Redshift on the Lake Formation console.
- Choose the pending catalog invitation and select Approve and create catalog.
- On the Set catalog particulars web page, configure your catalog:
- For Identify, enter a reputation (for this submit,
redshiftserverless1-uswest2). - Choose Entry this catalog from Apache Iceberg suitable engines.
- Select the IAM function you created for the information switch.
- Select Subsequent.
- For Identify, enter a reputation (for this submit,
- On the Grant permissions – non-obligatory web page, select Add permissions.
- Grant the
Adminconsumer Tremendous consumer permissions for Catalog permissions and Grantable permissions. - Select Add.
- Grant the
- Confirm the granted permission on the subsequent web page and select Subsequent.
- Assessment the small print on the Assessment and create web page and select Create catalog.
Wait a couple of seconds for the catalog to indicate up.
- Select Catalogs within the navigation pane and confirm that the
redshiftserverless1-uswest2catalog is created. - Discover the catalog element web page to confirm the
ordersdb.publicdatabase. - On the database View dropdown menu, view the desk and confirm that the
orderstbldesk reveals up.
Because the Admin function, you can even question the orderstbl in Amazon Athena and make sure the information is obtainable.
Grant permissions on the tables from the producer account to the buyer account
On this step, we share the Amazon Redshift federated catalog database redshiftserverless1-uswest2:ordersdb.public and desk orderstbl in addition to the Amazon S3 based mostly Iceberg desk returnstbl_iceberg and its database customerdb from the default catalog to the buyer account. We are able to’t share your entire catalog to exterior accounts as a catalog-level permission; we simply share the database and desk.
- On the Lake Formation console, select Knowledge permissions within the navigation pane.
- Select Grant.
- Beneath Principals, choose Exterior accounts.
- Present the buyer account ID.
- Beneath LF-Tags or catalog sources, choose Named Knowledge Catalog sources.
- For Catalogs, select the account ID that represents the default catalog.
- For Databases, select
customerdb. - Beneath Database permissions, choose Describe beneath Database permissions and Grantable permissions.
- Select Grant.
- Repeat these steps and grant table-level Choose and Describe permissions on
returnstbl_iceberg. - Repeat these steps once more to grant database- and table-level permissions for the
ordertbldesk of the federated catalog databaseredshiftserverless1-uswest2/ordersdb.
The next screenshots present the configuration for database-level permissions.
The next screenshots present the configuration for table-level permissions.
- Select Knowledge permissions within the navigation pane and confirm that the buyer account has been granted database- and table-level permissions for each
orderstblfrom the federated catalog andreturnstbl_icebergfrom the default catalog.
Register the Amazon S3 location of the returnstbl_iceberg with Lake Formation.
On this step, we register the Amazon S3 based mostly Iceberg desk returnstbl_iceberg information location with Lake Formation to be managed by Lake Formation permissions. Full the next steps:
- On the Lake Formation console, select Knowledge lake places within the navigation pane.
- Select Register location.
- For Amazon S3 path, enter the trail in your S3 bucket that you just supplied whereas creating the Iceberg desk
returnstbl_iceberg. - For IAM function, present the user-defined function
LakeFormationS3Registration_customthat you just created as a prerequisite. - For Permission mode, choose Lake Formation.
- Select Register location.
- Select Knowledge lake places within the navigation pane to confirm the Amazon S3 registration.
With this step, the producer account setup is full.
Steps for client account setup
For the buyer account setup, we use the IAM admin function Admin, added as a Lake Formation administrator.
The steps within the client account are fairly concerned. Within the client account, a Lake Formation administrator will settle for the AWS Useful resource Entry Supervisor (AWS RAM) shares and create the required useful resource hyperlinks that time to the shared catalog, database, and tables. The Lake Formation admin verifies that the shared sources are accessible by working check queries in Athena. The admin additional grants permissions to the function Glue-execution-role on the useful resource hyperlinks, database, and tables. The admin then runs a be part of question in AWS Glue 5.0 Spark utilizing Glue-execution-role.
Settle for and confirm the shared sources
Lake Formation makes use of AWS RAM shares to allow cross-account sharing with Knowledge Catalog useful resource insurance policies within the AWS RAM insurance policies. To view and confirm the shared sources from producer account, full the next steps:
- Log in to the buyer AWS console and set the AWS Area to match the producer’s shared useful resource Area. For this submit, we use
us-west-2. - Open the Lake Formation console. You will notice a message indicating there’s a pending invite and asking you settle for it on the AWS RAM console.
- Observe the directions in Accepting a useful resource share invitation from AWS RAM to evaluate and settle for the pending invitations.
- When the invite standing adjustments to Accepted, select Shared sources beneath Shared with me within the navigation pane.
- Confirm that the Redshift Serverless federated catalog
redshiftserverless1-uswest2, the default catalog databasecustomerdb, the deskreturnstbl_iceberg, and the producer account ID beneath Proprietor ID column show appropriately. - On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Databases.
- Search by the producer account ID.
You need to see thecustomerdbandpublicdatabases. You possibly can additional choose every database and select View tables on the Actions dropdown menu and confirm the desk names
You’ll not see an AWS RAM share invite for the catalog stage on the Lake Formation console, as a result of catalog-level sharing isn’t attainable. You possibly can evaluate the shared federated catalog and Amazon Redshift managed catalog names on the AWS RAM console, or utilizing the AWS Command Line Interface (AWS CLI) or SDK.
Create a catalog hyperlink container and useful resource hyperlinks
A catalog hyperlink container is a Knowledge Catalog object that references an area or cross-account federated database-level catalog from different AWS accounts. For extra particulars, seek advice from Accessing a shared federated catalog. Catalog hyperlink containers are primarily Lake Formation useful resource hyperlinks on the catalog stage that reference or level to a Redshift cluster federated catalog or Amazon Redshift managed catalog object from different accounts.
Within the following steps, we create a catalog hyperlink container that factors to the producer shared federated catalog redshiftserverless1-uswest2. Contained in the catalog hyperlink container, we create a database. Contained in the database, we create a useful resource hyperlink for the desk that factors to the shared federated catalog desk >:redshiftserverless1-uswest2/ordersdb.public.orderstbl.
- On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Catalogs.
- Select Create catalog.
- Present the next particulars for the catalog:
- For Identify, enter a reputation for the catalog (for this submit,
rl_link_container_ordersdb). - For Sort, select Catalog Hyperlink container.
- For Supply, select Redshift.
- For Goal Redshift Catalog, enter the Amazon Useful resource Identify (ARN) of the producer federated catalog (
arn:aws:glue:us-west-2:>:catalog/redshiftserverless1-uswest2/ordersdb). - Beneath Entry from engines, choose Entry this catalog from Apache Iceberg suitable engines.
- For IAM function, present the Redshift-S3 information switch function that you just had created within the conditions.
- Select Subsequent.
- For Identify, enter a reputation for the catalog (for this submit,
- On the Grant permissions – non-obligatory web page, select Add permissions.
- Grant the
Adminconsumer Tremendous consumer permissions for Catalog permissions and Grantable permissions. - Select Add after which select Subsequent.
- Grant the
- Assessment the small print on the Assessment and create web page and select Create catalog.
Wait a couple of seconds for the catalog to indicate up.
- Within the navigation pane, select Catalogs.
- Confirm that
rl_link_container_ordersdbis created.
Create a database beneath rl_link_container_ordersdb
Full the next steps:
- On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Databases.
- On the Select catalog dropdown menu, select
rl_link_container_ordersdb. - Select Create database.
Alternatively, you’ll be able to select the Create dropdown menu after which select Database.
- Present particulars for the database:
- For Identify, enter a reputation (for this submit,
public_db). - For Catalog, select
rl_link_container_ordersdb. - Go away Location – non-obligatory as clean.
- Beneath Default permissions for newly created tables, deselect Use solely IAM entry management for brand spanking new tables on this database.
- Select Create database.
- For Identify, enter a reputation (for this submit,
- Select Catalogs within the navigation pane to confirm that
public_dbis created beneathrl_link_container_ordersdb.
Create a desk useful resource hyperlink for the shared federated catalog desk
A useful resource hyperlink to a shared federated catalog desk can reside solely contained in the database of a catalog hyperlink container. A useful resource hyperlink for such tables won’t work if created contained in the default catalog. For extra particulars on useful resource hyperlinks, seek advice from Making a useful resource hyperlink to a shared Knowledge Catalog desk.
Full the next steps to create a desk useful resource hyperlink:
- On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Tables.
- On the Create dropdown menu, select Useful resource hyperlink.
- Present particulars for the desk useful resource hyperlink:
- For Useful resource hyperlink identify, enter a reputation (for this submit,
rl_orderstbl). - For Vacation spot catalog, select
rl_link_container_ordersdb. - For Database, select
public_db. - For Shared desk’s area, select US West (Oregon).
- For Shared desk, select
orderstbl. - After the Shared desk is chosen, Shared desk’s database and Shared desk’s catalog ID ought to get routinely populated.
- Select Create.
- For Useful resource hyperlink identify, enter a reputation (for this submit,
- Within the navigation pane, select Databases to confirm that
rl_orderstblis created beneathpublic_db, insiderl_link_container_ordersdb.
Create a database useful resource hyperlink for the shared default catalog database.
Now we create a database useful resource hyperlink within the default catalog to question the Amazon S3 based mostly Iceberg desk shared from the producer. For particulars on database useful resource hyperlinks, refer Making a useful resource hyperlink to a shared Knowledge Catalog database.
Although we’re in a position to see the shared database within the default catalog of the buyer, a useful resource hyperlink is required to question from analytics engines, akin to Athena, Amazon EMR, and AWS Glue. When utilizing AWS Glue with Lake Formation tables, the useful resource hyperlink must be named identically to the supply account’s useful resource. For extra particulars on utilizing AWS Glue with Lake Formation, seek advice from Issues and limitations.
Full the next steps to create a database useful resource hyperlink:
- On the Lake Formation console, beneath Knowledge Catalog within the navigation pane, select Databases.
- On the Select catalog dropdown menu, select the account ID to decide on the default catalog.
- Seek for
customerdb.
You need to see the shared database identify customerdb with the Proprietor account ID as that of your producer account ID.
- Choose
customerdb, and on the Create dropdown menu, select Useful resource hyperlink. - Present particulars for the useful resource hyperlink:
- For Useful resource hyperlink identify, enter a reputation (for this submit,
customerdb). - The remainder of the fields must be already populated.
- Select Create.
- For Useful resource hyperlink identify, enter a reputation (for this submit,
- Within the navigation pane, select Databases and confirm that
customerdbis created beneath the default catalog. Useful resource hyperlink names will present in italicized font.
Confirm entry as Admin utilizing Athena
Now you’ll be able to confirm your entry utilizing Athena. Full the next steps:
- Open the Athena console.
- Ensure that an S3 bucket is supplied to retailer the Athena question outcomes. For particulars, seek advice from Specify a question end result location utilizing the Athena console.
- Within the navigation pane, confirm each the default catalog and federated catalog tables by previewing them.
- You too can run a be part of question as follows. Take note of the three-point notation for referring to the tables from two totally different catalogs:
This verifies the brand new functionality of SageMaker Lakehouse, which permits accessing Redshift cluster tables and Amazon S3 based mostly Iceberg tables in the identical question, throughout AWS accounts, by way of the Knowledge Catalog, utilizing Lake Formation permissions.
Grant permissions to Glue-execution-role
Now we are going to share the sources from the producer account with further IAM principals within the client account. Normally, the information lake admin grants permissions to information analysts, information scientists, and information engineers within the client account to do their job capabilities, akin to processing and analyzing the information.
We arrange Lake Formation permissions on the catalog hyperlink container, databases, tables, and useful resource hyperlinks to the AWS Glue job execution function Glue-execution-role that we created within the conditions.
Useful resource hyperlinks enable solely Describe and Drop permissions. It’s essential to use the Grant heading in the right direction configuration to supply database Describe and desk Choose permissions.
Full the next steps:
- On the Lake Formation console, select Knowledge permissions within the navigation pane.
- Select Grant.
- Beneath Principals, choose IAM customers and roles.
- For IAM customers and roles, enter
Glue-execution-role. - Beneath LF-Tags or catalog sources, choose Named Knowledge Catalog sources.
- For Catalogs, select
rl_link_container_ordersdband the buyer account ID, which signifies the default catalog. - Beneath Catalog permissions, choose Describe for Catalog permissions.
- Select Grant.
- Repeat these steps for the catalog
rl_link_container_ordersdb:- On the Databases dropdown menu, select
public_db. - Beneath Database permissions, choose Describe.
- Select Grant.
- On the Databases dropdown menu, select
- Repeat these steps once more, however after selecting
rl_link_container_ordersdbandpublic_db, on the Tables dropdown menu, selectrl_orderstbl.- Beneath Useful resource hyperlink permissions, choose Describe.
- Select Grant.
- Repeat these steps to grant further permissions to
Glue-execution-role.- For this iteration, grant Describe permissions on the default catalog databases
publicandcustomerdb. - Grant Describe permission on the useful resource hyperlink
customerdb. - Grant Choose permission on the tables
returnstbl_icebergandorderstbl.
- For this iteration, grant Describe permissions on the default catalog databases
The next screenshots present the configuration for database public and customerdb permissions.
The next screenshots present the configuration for useful resource hyperlink customerdb permissions.
The next screenshots present the configuration for desk returnstbl_iceberg permissions.
The next screenshots present the configuration for desk orderstbl permissions.
- Within the navigation pane, select Knowledge permissions and confirm permissions on
Glue-execution-role.
Run a PySpark job in AWS Glue 5.0
Obtain the PySpark script LakeHouseGlueSparkJob.py. This AWS Glue PySpark script runs Spark SQL by becoming a member of the producer shared federated orderstbl desk and Amazon S3 based mostly returns desk within the client account to research the information and establish the entire orders positioned per market.
Exchange > within the script together with your client account ID. Full the next steps to create and run an AWS Glue job:
- On the AWS Glue console, within the navigation pane, select ETL jobs.
- Select Create job, then select Script editor.
- For Engine, select Spark.
- For Choices, select Begin contemporary.
- Select Add script.
- Browse to the situation the place you downloaded and edited the script, choose the script, and select Open.
- On the Job particulars tab, present the next data:
- For Identify, enter a reputation (for this submit,
LakeHouseGlueSparkJob). - Beneath Fundamental properties, for IAM function, select
Glue-execution-role. - For Glue model, choose Glue 5.0.
- Beneath Superior properties, for Job parameters, select Add new parameter.
- Add the parameters
--datalake-formats = icebergand--enable-lakeformation-fine-grained-access = true.
- For Identify, enter a reputation (for this submit,
- Save the job.
- Select Run to execute the AWS Glue job, and await the job to finish.
- Assessment the job run particulars from the Output logs
Clear up
To keep away from incurring prices in your AWS accounts, clear up the sources you created:
- Delete the Lake Formation permissions, catalog hyperlink container, database, and tables within the client account.
- Delete the AWS Glue job within the client account.
- Delete the federated catalog, database, and desk sources within the producer account.
- Delete the Redshift Serverless namespace within the producer account.
- Delete the S3 buckets you created as a part of information switch in each accounts and the Athena question outcomes bucket within the client account.
- Clear up the IAM roles you created for the SageMaker Lakehouse setup as a part of the conditions.
Conclusion
On this submit, we illustrated methods to convey your present Redshift tables to SageMaker Lakehouse and share them securely with exterior AWS accounts. We additionally confirmed methods to question the shared information warehouse and information lakehouse tables in the identical Spark session, from a recipient account, utilizing Spark in AWS Glue 5.0.
We hope you discover this convenient to combine your Redshift tables with an present information mesh and entry the tables utilizing AWS Glue Spark. Take a look at this resolution in your accounts and share suggestions within the feedback part. Keep tuned for extra updates and be happy to discover the options of SageMaker Lakehouse and AWS Glue variations.
Appendix: Desk creation
Full the next steps to create a returns desk within the Amazon S3 based mostly default catalog and an orders desk in Amazon Redshift:
- Obtain the CSV format datasets orders and returns.
- Add them to your S3 bucket beneath the corresponding desk prefix path.
- Use the next SQL statements in Athena. First-time customers of Athena ought to seek advice from Specify a question end result location.
- Create an Iceberg format desk within the default catalog and insert information from the CSV format desk:
- To create the orders desk within the Redshift Serverless namespace, open the Question Editor v2 on the Amazon Redshift console.
- Hook up with the default namespace utilizing your database admin consumer credentials.
- Run the next instructions within the SQL editor to create the database
ordersdband desk orderstbl in it. Copy the information out of your S3 location of the orders information to theorderstbl:
Concerning the Authors
Aarthi Srinivasan is a Senior Huge Knowledge Architect with Amazon SageMaker Lakehouse. She collaborates with the service crew to reinforce product options, works with AWS prospects and companions to architect lakehouse options, and establishes finest practices for information governance.
Subhasis Sarkar is a Senior Knowledge Engineer with Amazon. Subhasis thrives on fixing advanced technological challenges with modern options. He focuses on AWS information architectures, notably information mesh implementations utilizing AWS CDK elements.










{kind=link}