

Introduction
Stateful processing in Apache Spark™ Structured Streaming has developed considerably to fulfill the rising calls for of complicated streaming purposes. Initially, the applyInPandasWithState API allowed builders to carry out arbitrary stateful operations on streaming information. Nevertheless, because the complexity and class of streaming purposes elevated, the necessity for a extra versatile and feature-rich API turned obvious. To handle these wants, the Spark group launched the vastly improved transformWithStateInPandas API, obtainable in Apache Spark™ 4.0, which may now totally change the present applyInPandasWithState operator. transformWithStateInPandas offers far higher performance resembling versatile information modeling and composite sorts for outlining state, timers, TTL on state, operator chaining, and schema evolution.
On this weblog, we are going to give attention to Python to match transformWithStateInPandas with the older applyInPandasWithState API and use coding examples to indicate how transformWithStateInPandas can specific all the pieces applyInPandasWithState can and extra.
By the top of this weblog, you’ll perceive the benefits of utilizing transformWithStateInPandas over applyInPandasWithState, how an applyInPandasWithState pipeline might be rewritten as a transformWithStateInPandas pipeline, and the way transformWithStateInPandas can simplify the event of stateful streaming purposes in Apache Spark™.
Overview of applyInPandasWithState
applyInPandasWithState is a strong API in Apache Spark™ Structured Streaming that permits for arbitrary stateful operations on streaming information. This API is especially helpful for purposes that require customized state administration logic. applyInPandasWithState permits customers to control streaming information grouped by a key and apply stateful operations on every group.
A lot of the enterprise logic takes place within the func, which has the next kind signature.
For instance, the next perform does a working depend of the variety of values for every key. It’s value noting that this perform breaks the one duty precept: it’s accountable for dealing with when new information arrives, in addition to when the state has timed out.
A full instance implementation is as follows:
Overview of transformWithStateInPandas
transformWithStateInPandas is a brand new customized stateful processing operator launched in Apache Spark™ 4.0. In comparison with applyInPandasWithState, you’ll discover that its API is extra object-oriented, versatile, and feature-rich. Its operations are outlined utilizing an object that extends StatefulProcessor, versus a perform with a sort signature. transformWithStateInPandas guides you by providing you with a extra concrete definition of what must be applied, thereby making the code a lot simpler to cause about.
The category has 5 key strategies:
init: That is the setup technique the place you initialize the variables and many others. on your transformation.handleInitialState: This elective step helps you to prepopulate your pipeline with preliminary state information.handleInputRows: That is the core processing stage, the place you course of incoming rows of knowledge.handleExpiredTimers: This stage helps you to to handle timers which have expired. That is essential for stateful operations that want to trace time-based occasions.shut: This stage helps you to carry out any obligatory cleanup duties earlier than the transformation ends.
With this class, an equal fruit-counting operator is proven beneath.
And it may be applied in a streaming pipeline as follows:
Working with state
Quantity and kinds of state
applyInPandasWithState and transformWithStateInPandas differ when it comes to state dealing with capabilities and adaptability. applyInPandasWithState helps solely a single state variable, which is managed as a GroupState. This permits for easy state administration however limits the state to a single-valued information construction and kind. In contrast, transformWithStateInPandas is extra versatile, permitting for a number of state variables of various sorts. Along with transformWithStateInPandas's ValueState kind (analogous to applyInPandasWithState’s GroupState), it helps ListState and MapState, providing higher flexibility and enabling extra complicated stateful operations. These further state sorts in transformWithStateInPandas additionally convey efficiency advantages: ListState and MapState enable for partial updates with out requiring your entire state construction to be serialized and deserialized on each learn and write operation. This could considerably enhance effectivity, particularly with massive or complicated states.
applyInPandasWithState |
transformWithStateInPandas |
|
|---|---|---|
| Variety of state objects | 1 | many |
| Sorts of state objects | GroupState (Just like ValueState) |
ValueStateListStateMapState |
CRUD operations
For the sake of comparability, we are going to solely evaluate applyInPandasWithState’s GroupState to transformWithStateInPandas's ValueState, as ListState and MapState don’t have any equivalents. The largest distinction when working with state is that with applyInPandasWithState, the state is handed right into a perform; whereas with transformWithStateInPandas, every state variable must be declared on the category and instantiated in an init perform. This makes creating/establishing the state extra verbose, but additionally extra configurable. The opposite CRUD operations when working with state stay largely unchanged.
GroupState (applyInPandasWithState) |
ValueState (transformWithStateInPandas) |
|
|---|---|---|
| create | Creating state is implied. State is handed into the perform by way of the state variable. |
self._state is an occasion variable on the category. It must be declared and instantiated. |
def func(
key: _,
pdf_iter: _,
state: GroupState
) -> Iterator[pandas.DataFrame]
|
class MySP(StatefulProcessor):
def init(self, deal with: StatefulProcessorHandle) -> None:
self._state = deal with.getValueState("state", schema)
|
|
| learn |
state.get # or increase PySparkValueError state.getOption # or return None |
self._state.get() # or return None |
| replace |
state.replace(v) |
self._state.replace(v) |
| delete |
state.take away() |
self._state.clear() |
| exists |
state.exists |
self._state.exists() |
Let’s dig a bit of into among the options this new API makes doable. It’s now doable to
- Work with greater than a single state object, and
- Create state objects with a time to stay (TTL). That is particularly helpful to be used instances with regulatory necessities
applyInPandasWithState |
transformWithStateInPandas |
|
|---|---|---|
| Work with a number of state objects | Not Doable |
class MySP(StatefulProcessor):
def init(self, deal with: StatefulProcessorHandle) -> None:
self._state1 = deal with.getValueState("state1", schema1)
self._state2 = deal with.getValueState("state2", schema2)
|
| Create state objects with a TTL | Not Doable |
class MySP(StatefulProcessor):
def init(self, deal with: StatefulProcessorHandle) -> None:
self._state = deal with.getValueState(
state_name="state",
schema="c LONG",
ttl_duration_ms=30 * 60 * 1000 # 30 min
)
|
Studying Inside State
Debugging a stateful operation was difficult as a result of it was tough to examine a question’s inside state. Each applyInPandasWithState and transformWithStateInPandas make this simple by seamlessly integrating with the state information supply reader. This highly effective characteristic makes troubleshooting a lot less complicated by permitting customers to question particular state variables, together with a variety of different supported choices.
Under is an instance of how every state kind is displayed when queried. Be aware that each column, aside from partition_id, is of kind STRUCT. For applyInPandasWithState your entire state is lumped collectively as a single row. So it’s as much as the consumer to tug the variables aside and explode with a view to get a pleasant breakdown. transformWithStateInPandas offers a nicer breakdown of every state variable, and every component is already exploded into its personal row for simple information exploration.
| Operator | State Class | Learn statestore |
|---|---|---|
applyInPandasWithState |
GroupState |
show(
spark.learn.format("statestore")
.load("/Volumes/foo/bar/baz")
)
|
transformWithStateInPandas |
ValueState |
show(
spark.learn.format("statestore")
.possibility("stateVarName", "valueState")
.load("/Volumes/foo/bar/baz")
)
|
ListState |
show(
spark.learn.format("statestore")
.possibility("stateVarName", "listState")
.load("/Volumes/foo/bar/baz")
)
|
|
MapState |
show(
spark.learn.format("statestore")
.possibility("stateVarName", "mapState")
.load("/Volumes/foo/bar/baz")
)
|




Establishing the preliminary state
applyInPandasWithState doesn’t present a approach of seeding the pipeline with an preliminary state. This made pipeline migrations extraordinarily tough as a result of the brand new pipeline couldn’t be backfilled. Then again, transformWithStateInPandas has a way that makes this simple. The handleInitialState class perform lets customers customise the preliminary state setup and extra. For instance, the consumer can use handleInitialState to configure timers as nicely.
applyInPandasWithState |
transformWithStateInPandas |
|
|---|---|---|
| Passing within the preliminary state | Not doable |
.transformWithStateInPandas(
MySP(),
"fruit STRING, depend LONG",
"append",
"processingtime",
grouped_df
)
|
| Customizing preliminary state | Not doable |
class MySP(StatefulProcessor):
def init(self, deal with: StatefulProcessorHandle) -> None:
self._state = deal with.getValueState("countState", "depend LONG")
self.deal with = deal with
def handleInitialState(
self,
key: Tuple[str],
initialState: pd.DataFrame,
timerValues: TimerValues
) -> None:
self._state.replace((initialState.at[0, "count"],))
self.deal with.registerTimer(
timerValues.getCurrentProcessingTimeInMs() + 10000
)
|
So in the event you’re taken with migrating your applyInPandasWithState pipeline to make use of transformWithStateInPandas, you may simply accomplish that through the use of the state reader emigrate the interior state of the outdated pipeline into the brand new one.
Schema Evolution
Schema evolution is a vital facet of managing streaming information pipelines, because it permits for the modification of knowledge buildings with out interrupting information processing.
With applyInPandasWithState, as soon as a question is began, adjustments to the state schema should not permitted. applyInPandasWithState verifies schema compatibility by checking for equality between the saved schema and the energetic schema. If a consumer tries to change the schema, an exception is thrown, ensuing within the question’s failure. Consequently, any adjustments have to be managed manually by the consumer.
Clients often resort to certainly one of two workarounds: both they begin the question from a brand new checkpoint listing and reprocess the state, or they wrap the state schema utilizing codecs like JSON or Avro and handle the schema explicitly. Neither of those approaches is especially favored in apply.
Then again, transformWithStateInPandas offers extra sturdy help for schema evolution. Customers merely must replace their pipelines, and so long as the schema change is suitable, Apache Spark™ will mechanically detect and migrate the info to the brand new schema. Queries can proceed to run from the identical checkpoint listing, eliminating the necessity to rebuild the state and reprocess all the info from scratch. The API permits for outlining new state variables, eradicating outdated ones, and updating current ones with solely a code change.
In abstract, transformWithStateInPandas's help for schema evolution considerably simplifies the upkeep of long-running streaming pipelines.
| Schema change | applyInPandasWithState |
transformWithStateInPandas |
|---|---|---|
| Add columns (together with nested columns) | Not Supported | Supported |
| Take away columns (together with nested columns) | Not Supported | Supported |
| Reorder columns | Not Supported | Supported |
| Sort widening (eg. Int → Lengthy) | Not Supported | Supported |
Working with streaming information
applyInPandasWithState has a single perform that’s triggered when both new information arrives, or a timer fires. It’s the consumer’s duty to find out the explanation for the perform name. The best way to find out that new streaming information arrived is by checking that the state has not timed out. Subsequently, it is a finest apply to incorporate a separate code department to deal with timeouts, or there’s a threat that your code won’t work accurately with timeouts.
In distinction, transformWithStateInPandas makes use of totally different capabilities for various occasions:
handleInputRowsis known as when new streaming information arrives, andhandleExpiredTimeris known as when a timer goes off.
Because of this, no further checks are obligatory; the API manages this for you.
applyInPandasWithState |
transformWithStateInPandas |
|
|---|---|---|
| Work with new information |
def func(key, rows, state):
if not state.hasTimedOut:
...
|
class MySP(StatefulProcessor):
def handleInputRows(self, key, rows, timerValues):
...
|
Working with timers
Timers vs. Timeouts
transformWithStateInPandas introduces the idea of timers, that are a lot simpler to configure and cause about than applyInPandasWithState’s timeouts.
Timeouts solely set off if no new information arrives by a sure time. Moreover, every applyInPandasWithState key can solely have one timeout, and the timeout is mechanically deleted each time the perform is executed.
In distinction, timers set off at a sure time with out exception. You possibly can have a number of timers for every transformWithStateInPandas key, and so they solely mechanically delete when the designated time is reached.
Timeouts (applyInPandasWithState) |
Timers (transformWithStateInPandas) |
|
|---|---|---|
| Quantity per key | 1 | Many |
| Set off occasion | If no new information arrives by time x | At time x |
| Delete occasion | On each perform name | At time x |
These variations might sound refined, however they make working with time a lot less complicated. For instance, say you wished to set off an motion at 9 AM and once more at 5 PM. With applyInPandasWithState, you would want to create the 9 AM timeout first, save the 5 PM one to state for later, and reset the timeout each time new information arrives. With transformWithState, that is simple: register two timers, and it’s executed.
Detecting {that a} timer went off
In applyInPandasWithState, state and timeouts are unified within the GroupState class, that means that the 2 should not handled individually. To find out whether or not a perform invocation is due to a timeout expiring or new enter, the consumer must explicitly name the state.hasTimedOut technique, and implement if/else logic accordingly.
With transformWithState, these gymnastics are now not obligatory. Timers are decoupled from the state and handled as distinct from one another. When a timer expires, the system triggers a separate technique, handleExpiredTimer, devoted solely to dealing with timer occasions. This removes the necessity to test if state.hasTimedOut or not – the system does it for you.
applyInPandasWithState |
transformWithStateInPandas |
|
|---|---|---|
| Did a timer go off? |
def func(key, rows, state):
if state.hasTimedOut:
# sure
...
else:
# no
...
|
class MySP(StatefulProcessor):
def handleExpiredTimer(self, key, expiredTimerInfo, timerValues):
when = expiredTimerInfo.getExpiryTimeInMs()
...
|
CRUDing with Occasion Time vs. Processing Time
A peculiarity within the applyInPandasWithState API is the existence of distinct strategies for setting timeouts primarily based on processing time and occasion time. When utilizing GroupStateTimeout.ProcessingTimeTimeout, the consumer units a timeout with setTimeoutDuration. In distinction, for EventTimeTimeout, the consumer calls setTimeoutTimestamp as a substitute. When one technique works, the opposite throws an error, and vice versa. Moreover, for each occasion time and processing time, the one approach to delete a timeout is to additionally delete its state.
In distinction, transformWithStateInPandas affords a extra easy method to timer operations. Its API is constant for each occasion time and processing time; and offers strategies to create (registerTimer), learn (listTimers), and delete (deleteTimer) a timer. With transformWithStateInPandas, it’s doable to create a number of timers for a similar key, which enormously simplifies the code wanted to emit information at varied time limits.
applyInPandasWithState |
transformWithStateInPandas |
|
|---|---|---|
| Create one |
state.setTimeoutTimestamp(tsMilli) |
self.deal with.registerTimer(tsMilli) |
| Create many | Not doable |
self.deal with.registerTimer(tsMilli_1) self.deal with.registerTimer(tsMilli_2) |
| learn |
state.oldTimeoutTimestamp |
self.deal with.listTimers() |
| replace |
state.setTimeoutTimestamp(tsMilli) # for EventTime state.setTimeoutDuration(durationMilli) # for ProcessingTime |
self.deal with.deleteTimer(oldTsMilli) self.deal with.registerTimer(newTsMilli) |
| delete |
state.take away() # however this deletes the timeout and the state |
self.deal with.deleteTimer(oldTsMilli) |
Working with A number of Stateful Operators
Chaining stateful operators in a single pipeline has historically posed challenges. The applyInPandasWithState operator doesn’t enable customers to specify which output column is related to the watermark. Because of this, stateful operators can’t be positioned after an applyInPandasWithState operator. Consequently, customers have needed to break up their stateful computations throughout a number of pipelines, requiring Kafka or different storage layers as intermediaries. This will increase each price and latency.
In distinction, transformWithStateInPandas can safely be chained with different stateful operators. Customers merely must specify the occasion time column when including it to the pipeline, as illustrated beneath:
This method lets the watermark info cross by way of to downstream operators, enabling late document filtering and state eviction with out having to arrange a brand new pipeline and intermediate storage.
Conclusion
The brand new transformWithStateInPandas operator in Apache Spark™ Structured Streaming affords vital benefits over the older applyInPandasWithState operator. It offers higher flexibility, enhanced state administration capabilities, and a extra user-friendly API. With options resembling a number of state objects, state inspection, and customizable timers, transformWithStateInPandas simplifies the event of complicated stateful streaming purposes.
Whereas applyInPandasWithState should be acquainted to skilled customers, transformWithState's improved performance and flexibility make it the higher alternative for contemporary streaming workloads. By adopting transformWithStateInPandas, builders can create extra environment friendly and maintainable streaming pipelines. Strive it out for your self in Apache Spark™ 4.0, and Databricks Runtime 16.2 and above.
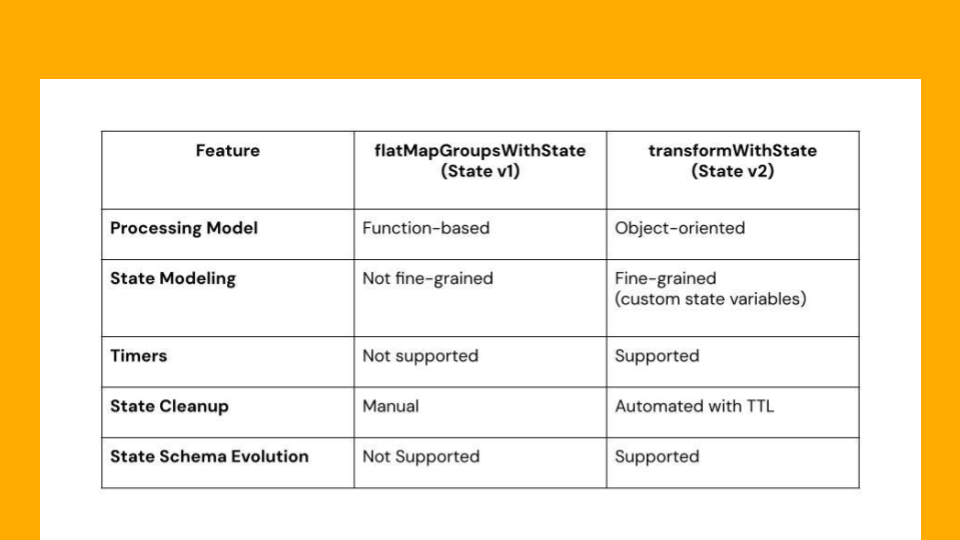
| Function | applyInPandasWithState (State v1) | transformWithStateInPandas (State v2) |
|---|---|---|
| Supported Languages | Scala, Java, and Python | Scala, Java, and Python |
| Processing Mannequin | Operate-based | Object-oriented |
| Enter Processing | Processes enter rows per grouping key | Processes enter rows per grouping key |
| Output Processing | Can generate output optionally | Can generate output optionally |
| Supported Time Modes | Processing Time & Occasion Time | Processing Time & Occasion Time |
| Advantageous-Grained State Modeling | Not supported (solely single state object is handed) | Supported (customers can create any state variables as wanted) |
| Composite Sorts | Not supported | Supported (presently helps Worth, Listing and Map sorts) |
| Timers | Not supported | Supported |
| State Cleanup | Guide | Automated with help for state TTL |
| State Initialization | Partial Help (solely obtainable in Scala) | Supported in all languages |
| Chaining Operators in Occasion Time Mode | Not Supported | Supported |
| State Information Supply Reader Help | Supported | Supported |
| State Mannequin Evolution | Not Supported | Supported |
| State Schema Evolution | Not Supported | Supported |











{kind=link}